
Information Extraction System
Scanned PDF Data Extraction System
Developed a web-based document intelligence platform that automatically extracts structured information from scanned PDF documents. The system identifies and extracts key entities such as document type, title, company names, addresses, and dates from unstructured scanned files.
The platform combines computer vision, OCR, and natural language processing to transform scanned documents into structured data that can be stored, searched, and analyzed.
Purpose
- Automatically process scanned PDF documents
- Extract important information from unstructured text
- Classify document types
- Identify key entities such as organizations, addresses, and dates
- Provide a web interface for document processing
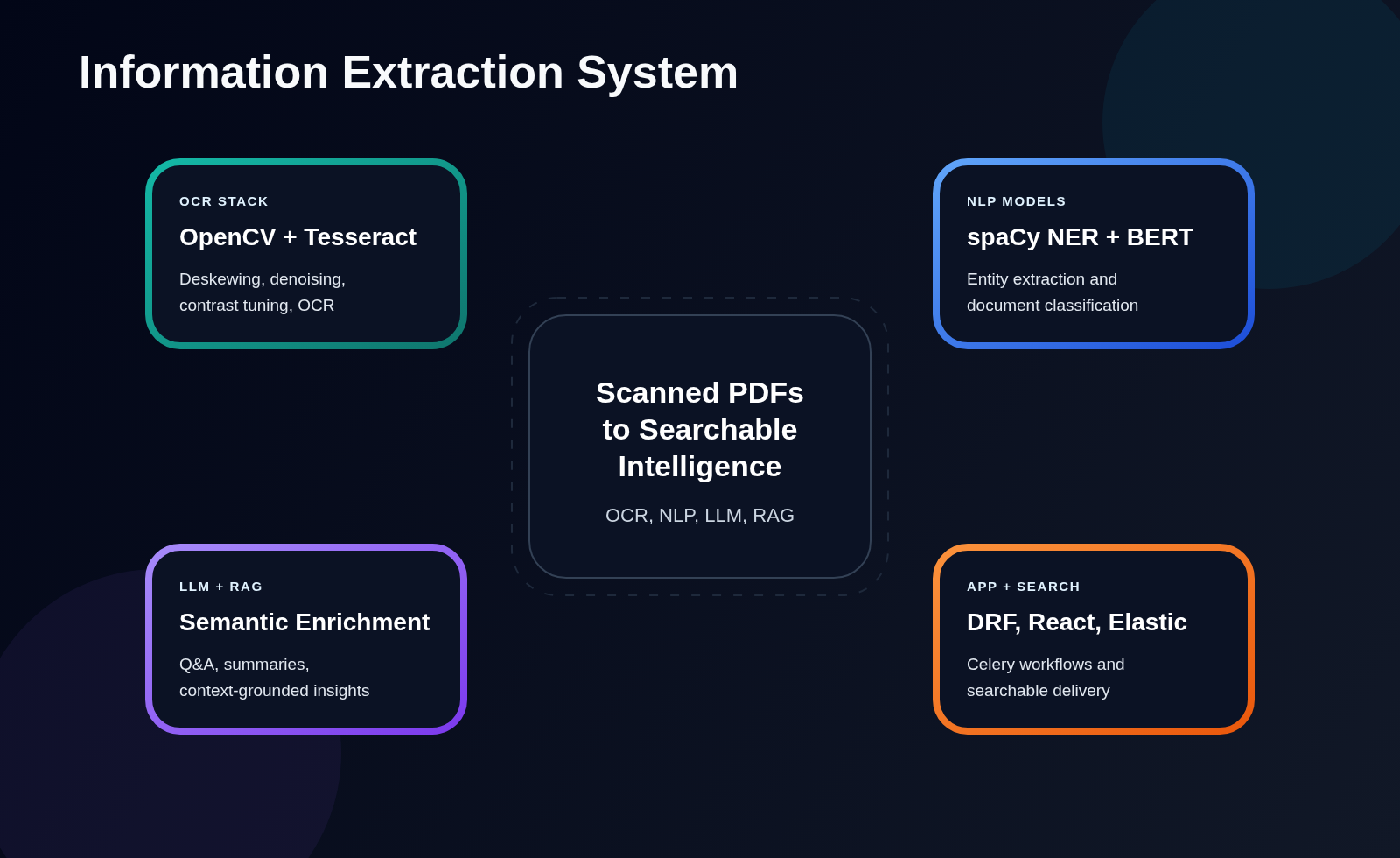
System Architecture
- Document Processing Pipeline
- Optical Character Recognition
- Natural Language Processing
- Web Application
Results & Impact
- Automated Contract Data Extraction
- Improved OCR Accuracy Through Image Preprocessing
- Faster Document Processing
- Better Searchability & Structured Data Use
- Reduced Operational Overhead
- Scalable Cloud-Native Processing